通过发布 AndioSet,我们希望能为音频事件检测提供一个常见的、实际的评估任务,也是声音事件的综合词汇理解的一个开端。
大型数据收集
该数据集收集了所有与我们合作的人类标注者从 YouTube 视频中识别的声音。我们基于 YouTube 元数据和基于内容的搜索来挑选需要标注的片段。
在我们的音频本体中,得到的数据集在音频事件类上有极好的覆盖。
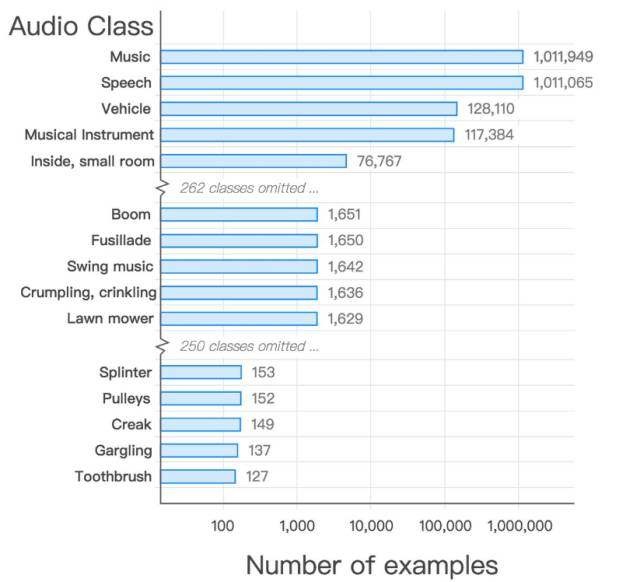
图:每类别样本的数量
在我们 ICASSP 2017 论文中音频本体和数据集的构建有更加具体的描述。你可以在我们 GitHub 知识库中为音频本体作更多补充。数据集与机器提取特征(machine-extracted features)已可以下载 https://github.com/audioset/ontology
此项研究成果已经以论文的形式发表在了 IEEE ICASSP 2017 大会上:
论文:Audio Set: An ontology and human-labeled dataset for audio events
摘要
音频事件识别,类似人类识别音频事件并进行关联的能力,是机器感知研究中的一个新生问题。类似问题,比如识别图像中的目标研究已经从广泛数据集——主要是 ImageNet 中获益匪浅。这篇论文描述了大规模人工标记音频事件数据组 Audio Set 的建造过程。该数据组旨在弥合图片和音频研究之间存在的鸿沟。使用文献和人工管理指导下精细建构起来的 635 个音频类别的层级本体,我们搜集了源自人工标记者的大量数据,探查特定音频类别(10 秒时长的 YouTube 音频片段)的现状。建议使用基于元数据、文本(比如链接)以及内容分析的搜索对这些片段进行标记。结果,我们获得了一个宽度和大小都史无前例的数据集,我们希望它能实质上促进高水平音频事件识别程序的发展。
AudioSet提供了两种格式:
csv文件,包括音频所在的YouTube视频的ID,开始时间,结束时间 以及标签(可能是多标签)
128维的特征,采样率为1Hz,也就是把音频按秒提取为128维特征。特征是使用VGGish模型来提取的,VGGish下载地址为 TensorFlow models GitHub repository,可以使用该模型提取我们自己的数据。VGGish也是用来提取YouTube-8M的。这些数据被存储为.tfrecord格式。
128维特征的下载地址(基于所在地)
http://storage.googleapis.com/us_audioset/youtube_corpus/v1/features/features.tar.gz
http://storage.googleapis.com/eu_audioset/youtube_corpus/v1/features/features.tar.gz
http://storage.googleapis.com/asia_audioset/youtube_corpus/v1/features/features.tar.gz
其中,label的类型映射对应,可以通过class_labels_indices.csv了解。
AudioSet还提供了Starter Code用来在AudioSet上进行训练,以便作为baseline,这代码也是用来在YouTube8M上训练的,代码可以在Starter Code下载
更多的细节,可以在Google的论坛AudioSet_User了解。